As always I not only provide the toolbox but also a dataset to try it out. Let's start from here...
Data
For testing the plotting tool, I downloaded some air pollution data from EPA (US Environmental Protection Agency), which provides open access to its database. I created a custom function to download data from EPA that you can find in this post.
Since I wanted to provide a relatively small dataset, I extracted values from only four states: California, New York, Iowa and Ohio. For each of these, I included time series for Temperature, CO, NO2, SO2 and Barometric Pressure. Finally, the coordinates of the points are the centroid for each of these four states. The image below depicts the location and the first lines of the attribute table. This dataset is provided in shapefile and CSV, both can be used with the plotting toolbox.

Toolbox
Now that we have seen the sample dataset, we can take a look at the toolbox. I included 5 packages to help summarize and visualize spatial data directly from the ArcGIS console.

I first included a package for summarizing our variables, this creates a table with some descriptive statistics. Then I included all the major plotting types I presented in my book "Learning R for Data Visualization [VIDEO]" edited by Packt Publishing, with some modifications to the scripts for adapting them to the R-Bridge Technology from ESRI. For more information, practical and theoretical, about each of these plots please refer to the book.
The tool can be downloaded from my GitHub page at:
https://github.com/fveronesi/PlottingToolbox
Summary
This is the first package I would like to describe simply because a data analysis should always start with a look at our variables with some descriptive statistics. As for all the tools presented here its use is simple and straightforward with the GUI presented below:

Here the user has to point to the dataset s/he wants to analyze in "Input Table". This can be a shapefile, either loaded already in ArcGIS or not, but it can also be a table, for example a CSV. That is the reason why I included a CSV version of the EPA dataset as well.
At this point the area in "Variable" will fill up with the column names of the input file, from here the user can select the variable s/he is interested in summarizing. The final step is the selection of the "Output Folder". Important: users need to first create the folder and then select it. This is because this parameter is set as input, so the folder needs to exist. I decided to do it this way because otherwise for each new plot a new folder would have need to be created. This way all the summaries and plots can go into the same directory.
Let's take a look at the results:
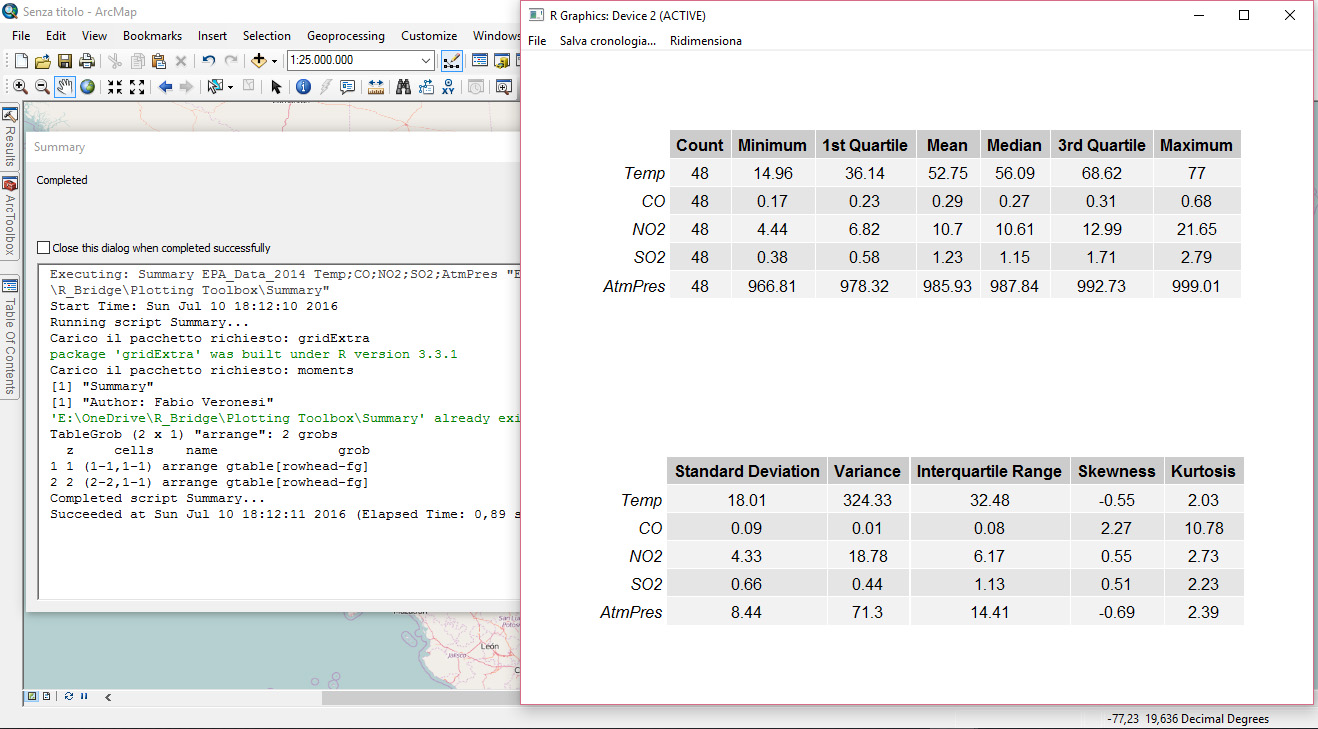
The Summary package presents two tables, with all the variables we wanted to summarize, arranged one above the other. This is the output users will see on screen once the toolbox has competed its run. Then in the output folder, the R script will save this exact table in PDF format, plus a CSV with the raw data.
Histogram
As the name suggest this tool provides access to the histogram plot in ggplot2. ArcGIS provides a couple of ways to represent data in histograms. The first way is by clicking with the right mouse button on one of the column in the attribute table; a drop-down menu will appear and from there users can click on "Statistics" to access some descriptive statistics and a histogram. Another way is through the "Geostatistical Analyst", which is an add-on for which users need an additional license. This has an "Explore Data" package from which it is possible to create histograms. The problem with both these methods is that the results are not, in my opinion at least, suitable for any publication. You can maybe share them with your colleagues, but I would not suggest using them for any article. This implies that ArcGIS users need to open another software, maybe Excel, to create the plots they require, and we all know how painful it is in Excel to produce any decent plot, and histogram are probably the most painful to produce.
This changes now!!
By combining the power of R and ggplot2 with ArcGIS we can provide users with an easy to use way to produce beautiful visualizations directly within the ArcGIS environment and have them saved in jpeg at 300 dpi. This is what this set of packages does.
Let's now take a look at the interface for histograms:

As for Summary we first need to insert the input dataset, and then select the variable/s we want to plot. If two or more variables are selected, several plots will be created and saved in jpeg.
I also added some optional values to further customize the plots. The first is the faceting variable, which is a categorical variable. If this is selected the plot will have a histogram for each category; for example, in the sample dataset I have the categorical variable "state", with the name of the four states I included. If I select this for faceting the result will be the figure below:

Another option available here is the binwidth. The package ggplot2 usually sets this number as the range of the variable divided by 30. However, this can be customized by the user and this is what you can do with this option. Finally users need to specify an output folder where R will save a jpeg of the plots shown on screen.
Box-Plot
This is another great way to compare variables' distributions and as far as I know it cannot be done directly from ArcGIS. Let's take a look at this package:

This is again very easy to use. Users just need to set the input file, then the variable of interest and the categorical variable for the grouping. Here I am again using the states, so that I compare the distribution of NO2 across the four US states in my dataset.
The results is ordered by median values and it is shown below:

As you can see I decided to plot the categories vertically, as to accomodate long names. This of course can be changed by tweaking the R script. As for each package, this plot is saved in the output folder.
Bar Chart
This tool is generally used to compare different values for several categories, but generally we have one value for each category. However, it may happen that the dataset contains multiple measurements for some categories, and I implemented a way to deal with that here. Below is presented the GUI to this package:

The inputs are basically the same as for box-plots, the only difference is in the option "Average Values". If this is set, R will average the values of the variable for each unique category in the dataset. The results are again ordered, and are saved in jpeg in the output folder:

Scatterplot
This is another great way to visually analyze our data. The package ggplot2 allows the creation of highly customized plots and I tried to implement as much as I could in terms of customization in this toolbox. Let's take a look:

After selecting the input dataset the user can select what to plot. S/he can choose to only plot two variables, one on the X axis and one on the Y axis, or further increase the amount of information presented in the plot by including a variable that changes the color of the points and one for their size. Moreover, there is also the possibility to include a regression line. Color, size and regression line are optional, but I wanted to include them to present the full range of customizations that this package allows.

Once again this plot is saved in the output folder.
Time Series
The final type of plots I included here is the time series, which is also the one with the highest number of inputs from the user side. In fact, many spatial datasets include a temporal component but often time this is not standardized. By that I mean that in some cases the time variable has only a date, and in some cases it includes a time; in other cases the format changes from dataset to dataset. For this reason it is difficult to create an R script that works with most datasets, therefore for time-series plots users need to do some pre-processing. For example, if date and time are in separate columns, these need to be merged into one for this R script to work.
At this point the TimeSeries package can be started:

The first two columns are self explanatory. Then users need to select the column with the temporal information, and then input manually the format of this column.
In this case the format I have in the sample dataset is the following: 2014-01-01
Therefore I have the year with century, a minus sign, the month, another minus sign and the day. I need to use the symbols for each of these to allow R to recognize the temporal format of the file.
Common symbol are:
%Y - Year with century
%y - Year without century
%m - Month
%d - Day
%H - Hour as decimal number (00-23)
%M - Minute as decimal number (00-59)
%S - Second as decimal number
More symbols can be found at this page: http://www.inside-r.org/r-doc/base/strptime
The remaining two inputs are optional, but if one is selected the other needs to be provided. For "Subsetting Column" I intend a column with categorical information. For example, in my dataset I can generate a time-series for each US state, therefore my subsetting column is state. In the option "Subset" users need to write manually the category they want to use to subset their data. Here I just want to have the time-series for California, so I write California. You need to be careful here to write exactly the name you see in the attribute table because R is case sensitive, thus if you write california with a lower case c R will be unable to produce the plot.
The results, again saved in jpeg automatically, is presented below: