In this post I would like to present a toolbox to perform some introductory point pattern analysis in R through ArcGIS. Basically, I developed a toolbox to perform the tests I presented in my previous post about point pattern analysis. In there, you can find some theoretical concepts that you need to know to understand what this toolbox can do.
I will start by introducing the sample dataset we are going to use, and then simply show the packages available.
Dataset
For presenting this toolbox I am using the same dataset I used for my previous post, namely the open crime data from the UK. For this post I downloaded crimes in the London area from the whole 2015. As you can see from the image below we are talking about more than 950'000 crimes of several categories, all across London.

I also included a polygon shapefile with the area around London and all its boroughs, this should be visible as blue lines around the city. I included this because point pattern analysis requires the user to set the border of the study area, as I mentioned in my previous post.
Spatio-Temporal Subset
The first package I would like to present is a simple spatio-temporal subsetting tool. This is completely based on R but it is basically a more flexible version of the selection tools available in ArcGIS.

Here users can select points based on various parameters at once. For example, they can subset the polygon shapefile, for example here I'm extracting the borough of Ealing, and extract points only for this area. Then they can subset by time, with the same strings I presented in my previous post about a toolbox for time series analysis. Optionally, they can also subset the dataset itself based on some categories. In this example I'm extracting only the drug related crimes, committed in Ealing in May 2015.
It is important to point out that in this first version of the toolbox users can only select one element in the SQL statements. For example here I have "name" = 'Ealing'. In ArcGIS users could also put an AND and then specify another option. However, in the R code I did not put a way to deal with multiple inputs and conditions (e.g. AND, OR) and therefore only one option can be specified.
The result is a new shapefile, plotted directly on the ArcGIS console with the required subset of the data, as shown below:

Spatio-Temporal Centroid
As you may already know, ArcGIS provides a function to calculate the centroid of a point pattern. However, if we wanted to test for changes in the centroid location with time we would need to first subset our data and then compute the centroid. What I did in this package is merge these two actions into one. This package, presented in the image below, loops through the dataset, subsetting the point pattern by time (users can choose between daily, monthly and yearly subsets) and then calculates the centroid for each time unit. Moreover, I also added an option to select the statistics to use between mean, median and mode.

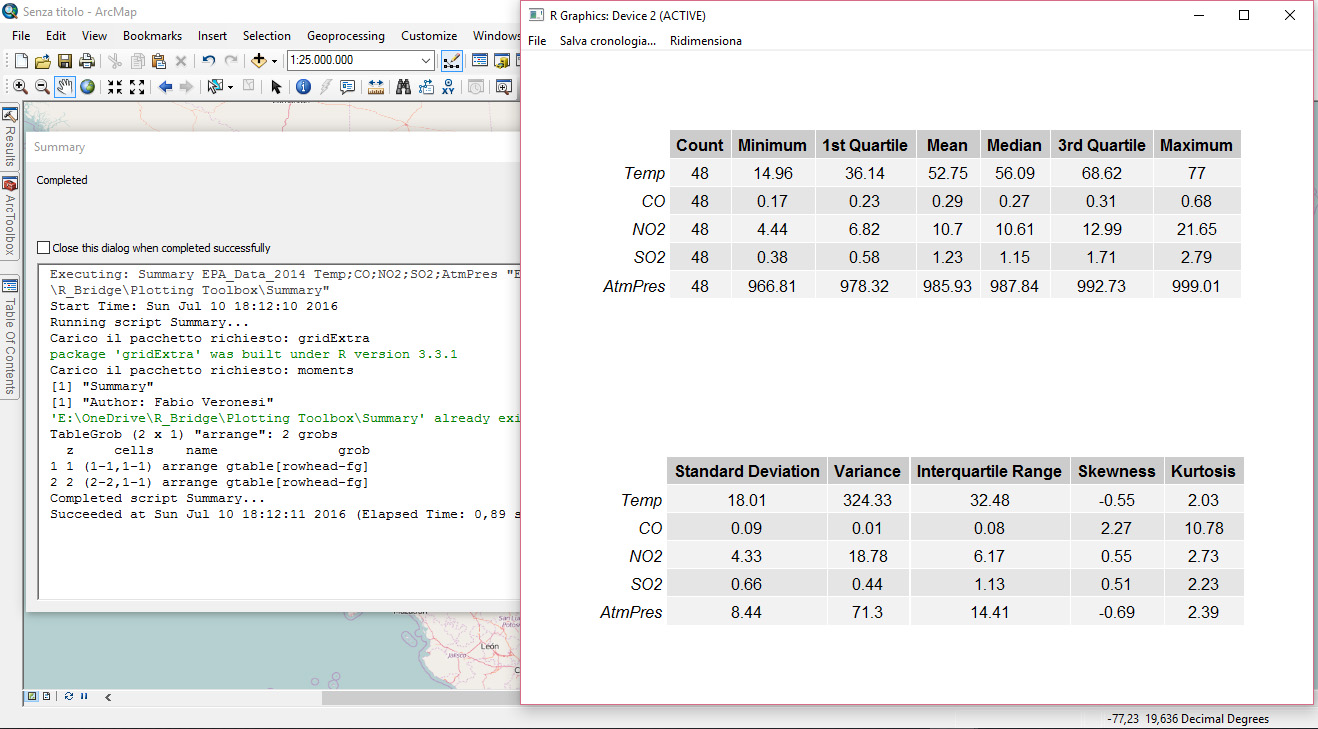
The results for the three statistics are presented below:

Spatio-Temporal Density
This tool calculates the point density for specific regions and time frames by subsetting your dataset. This is something that you may be able to obtain directly from ArcGIS, but users would need to first subset their data and then perform the density analysis, this tool groups those two things into one. Moreover, the package spatstat, which is used in R for point pattern analysis has some clear advantages compared to the tool available in ArcGIS. For example, as I mentioned in my post it provides ways to calculate the best bandwidth for the density estimation. In the script this is achieved using the function bw.ppl, but this can be changed if you need a different method, you just need to replace this function with another. Moreover, as pointed out in this tutorial, ArcGIS does not correct for edge effects.
Working with this package is very similar to the others I presented before:

Users need to specify the input point pattern, then a polygon shapefile for the study area, which can be subset to reduce the area under investigation. Then users can include a temporal subsetting (here I used the string "2015-10/" which means from October to the end of the year, please refer to this post for more info) and subset their data extracting a certain category of crimes. Again here the SQL statements cannot include more than one category.
Finally, users need to provide a raster dataset for saving the density result. This needs to be a .tif file, otherwise in my tests the result did not appear on screen. The output of this script is the image below, for the borough of Bromley and only for robberies:

Spatio-Temporal Randomness
This is another tool to perform a test for spatial randomness, the G function I explained in my previous post, but on a subset of the main dataset. In fact, this test is available in ArcGIS under "Multi-Distance Spatial Cluster Analysis (Ripleys K Function)", but in this case we are again performing it on a particular subset of our data.
The GUI is very similar to the other I presented before:

The only difference is that here users also need to provide an output folder, where the plot created by R will be saved in jpeg at 300 dpi. Moreover, this tool also provides users with the point shapefile created by subsetting the main dataset.
The output for the borough of Tower Hamlets and only for drug related crimes in March 2015 is the plot below:

Spatio-Temporal Correlogram
As the name suggests I develop this tool to calculate and plot a correlogram on a spatio-temporal subset of my data. For this example I could not use the crime dataset, since I do not have a continuous variable in it. Therefore I loaded the dataset of ozone measurements from sensors installed on trams here in Zurich that I used for my post about spatio-temporal kriging. This tool uses the function correlog from the package xts to calculate the correlogram. This function takes several arguments among which an increment, the number of permutations and a TRUE/FALSE flag if data are unprojected or not. These are all data that users will need to input once they use the tool and are additional options in the GUI, which for the other points is more or less identical to what I presented before, except for the selection of the variable of interest:

The result is the image below, which is again saved in jpeg at 300 dpi. As for the spatio-temporal randomness tool, a shapefile with the spatio-temporal subset used to calculate the correlogram is also saved and opened in ArcGIS directly.

Download
The tool is available, along with the sample data, from my GitHub archive:
https://github.com/fveronesi/Spatio-Temporal-Point-Pattern-Analysis